Scaling Down an Elasticsearch Cluster

This is a very technical post about the very popular Elasticsearch technology we are partly using in the Mapillary backend. Normally, everything is about scaling up. However, this time we upgraded to a higher version of Elasticsearch and wanted to keep the old cluster (Elasticsearch 1.7) around for a while in order to migrate data and to do some legacy searches. We of course wanted to scale it down in order to save hardware.
Here is a small guide on how to do it, since it turned out to be less trivial then just switching off machines if you really want to scale this down to the storage limits.
Snapshots versus downscaling
First, think about if you need the cluster to be online at all. If not, just save snapshots and bring them online later if you need them, instructions here. Snapshots can be restored even into normally incompatible versions, so this is a good alternative and you can skip the rest of this article.
Preparations
There are some first things to consider that are quite easy to do and will free a lot of resources.
- Back up your cluster to have something to restore if things go wrong down the line.
- Stop all writes to your cluster as it will not be safe to fail over after our downscaling.
- Check disk space so you can fit the data on your nodes onto the remaining ones.
- Bring down the index replication factor to 1 in order to save space and speed up shard relocation during scaling, since less shards need to be created and moved around. Also, this saves a lot of space in duplicated data.
curl -XPUT http://my.els.clust.er/mapimages/_settings -d '
{
"index" : {
"number_of_replicas" : 1
}
}'
- If you have not enabled master on index nodes, do so now (will require restart of these nodes, so do it while the cluster still can rebalance gracefully).
Phase 1 - Elasticsearch is handling this for you
We are now removing failover nodes that are not strictly necessary for the cluster to function and will not trigger any data shuffling—these nodes are normally there for production failover scenarios and can be safely removed in a sporadic-access-setting.
- Remove master nodes failovers—the data nodes are now master-enabled.
- Remove slave nodes failovers—all nodes will be serving as potential read nodes.
 The current state of the cluster with one read and one master node, 7 data nodes
The current state of the cluster with one read and one master node, 7 data nodes
- Remove the last read node (all nodes can be read from, but you will need to point your cluster entry point or load balancer to one of the data nodes you intend to keep around after the downscale).
- Kill the last master (master will now go to one of the data nodes that formerly couldn't be elected).
Phase 2 - moving data using Elasticsearch rebalancing
Here, we scale down using the built-in cluster data balancing capabilities of Elasticsearch without worrying about consistency and data loss.
- Switch shard allocation on so the cluster can rebalance when you remove nodes.
curl -XPUT http://my.els.clust.er/els/_cluster/settings -d '{
"transient" : {
"cluster.routing.allocation.enable" : "all"
}
}'
- Remove one data node — the cluster will go into yellow state.
- Wait for green—then the cluster has replicated the lost shards.
- Monitor disk usage on the remaining data nodes so you don't run into high watermark issues. You might want to attach bigger disks and bring up new nodes in order to fit things in.
Phase 3 - remove replicas
Now we are getting into more dangerous territory. We want to further remove cluster nodes, but don't have replicas to back up the shards.
- Per index, set the number of replicas to 0 in order to save space. This cuts the cluster's disk requirements in half, however you will have no more easy scaling since there are no replicas to fail over to if you remove nodes from the cluster.
curl -XPUT http://my.els.clust.er/mapimages/_settings -d '
{
"index" : {
"number_of_replicas" : 0
}
}'
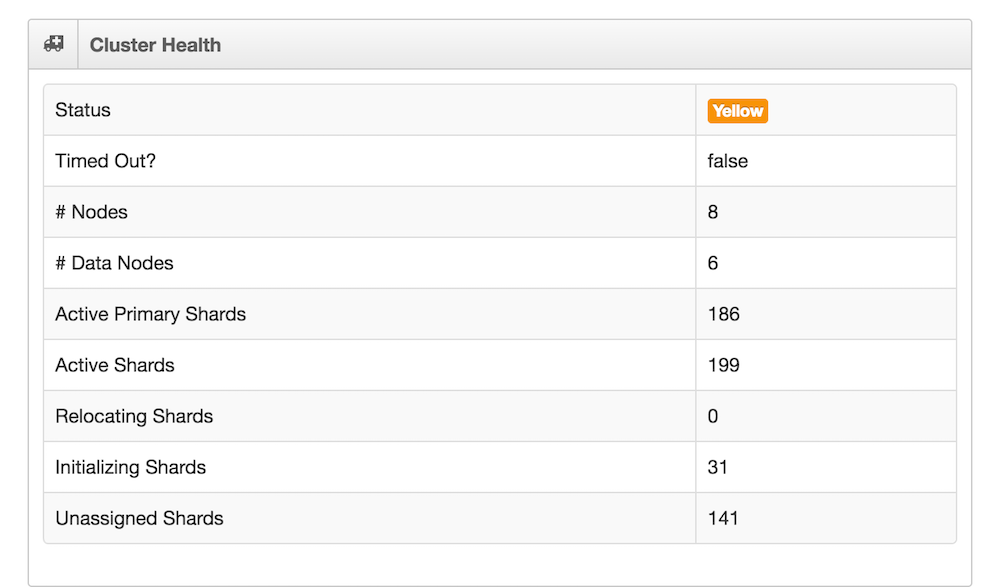 The yellow indicates no replicas, but all primaries online
The yellow indicates no replicas, but all primaries online
Phase 4 - move primaries off data nodes explicitly
Now, explicitly move primary shards from the nodes to empty onto nodes that should be left online. This will first create a replica on the target node, then make the replica the primary, and lastly delete the old primary.
- Disable shard allocation to prevent shards from moving around, since we actually want to clean one node from critical data.
curl -XPUT http://my.els.clust.er/_cluster/settings -d '{
"transient" : {
"cluster.routing.allocation.enable" : "none"
}
}'
Here is a sample script using the Elasticsearch cat API:
#!/usr/bin/env bash
# The script performs force relocation of all unassigned shards,
# of all indices to a specified node (NODE variable)
ES_HOST="http://my.els.clust.er/"
TARGET_NODE="els-cluster-1-node-8"
curl ${ES_HOST}/_cat/shards > shards
grep "els-cluster-1-node-3" shards > unassigned_shards
# Now move all shard in the unnasigned_shards file onto the target node
while read LINE; do
IFS=" " read -r -a ARRAY <<< "$LINE"
INDEX=${ARRAY[0]}
SHARD=${ARRAY[1]}
echo "Relocating:"
echo "Index: ${INDEX}"
echo "Shard: ${SHARD}"
echo "To node: ${TARGET_NODE}"
curl -s -XPOST "${ES_HOST}/_cluster/reroute" -d "{
\"commands\": [
{
\"allocate\": {
\"index\": \"${INDEX}\",
\"shard\": ${SHARD},
\"node\": \"${TARGET_NODE}\",
\"allow_primary\": true
}
}
]
}"; echo
echo "------------------------------"
done <unassigned_shards
exit 0
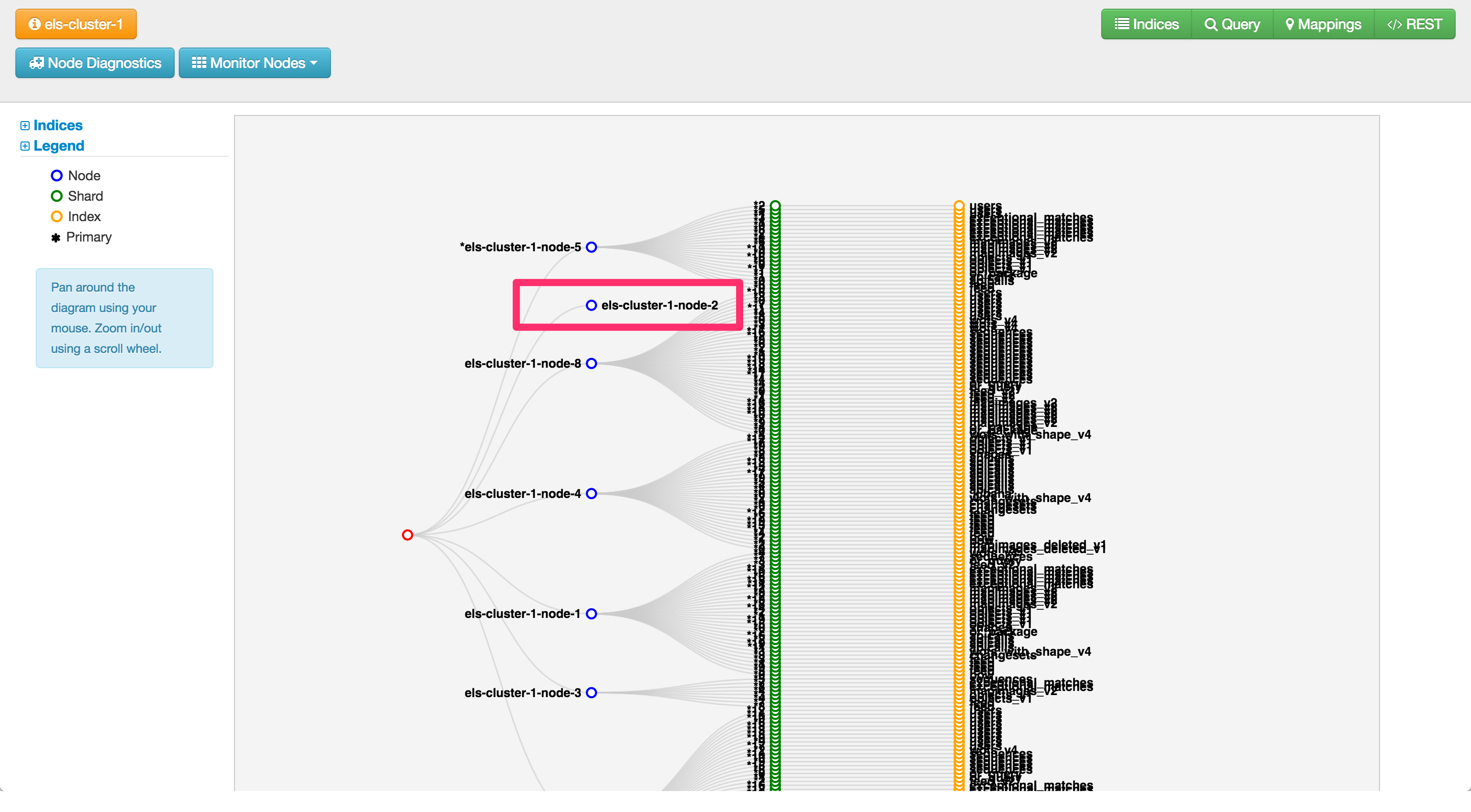 cluster-node-2 does not have any allocated shards now and can be removed
cluster-node-2 does not have any allocated shards now and can be removed
Phase 5 - kill the now empty data nodes
After the node is clean, you can remove if from the cluster without any negative impact. As long as you have space left on the remaining data nodes, you can scale it down further.
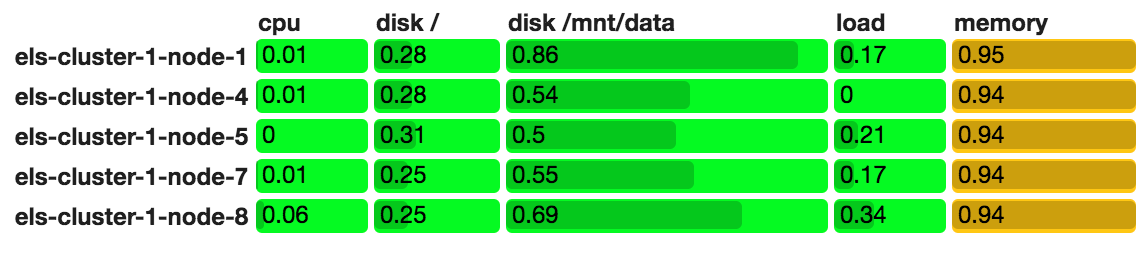 The cluster is now only 5 data nodes big
The cluster is now only 5 data nodes big
Happy downscaling,
/peter