Map Data in the Era of Autonomous Driving

Map data is one of the key assets to enable autonomous driving in the future. At the same time, self-driving cars are a completely new type of map user, putting a new level of demands on what these maps need to be like.
In the era of autonomous driving, we need map data that is:
Accurate—allowing to localize the vehicle in its surroundings.
Comprehensive—embedding different navigation and localization information such as detailed traffic signs, lanes and much more.
Fresh—enabling easy and constant live updates of critical map information.
Accessible—available in all drivable areas.
Compact—capable of efficient data transfer for localization and map updates.
It’s a challenge to hit all those targets at the same time. There tends to be a trade-off that applies to lots of other things besides map data—to produce something fast and in large quantities, it can easily compromise the quality and comprehensiveness, and vice versa. At Mapillary, we believe the solution lies in combining collaboration and computer vision. Here is a closer look at how this approach works.
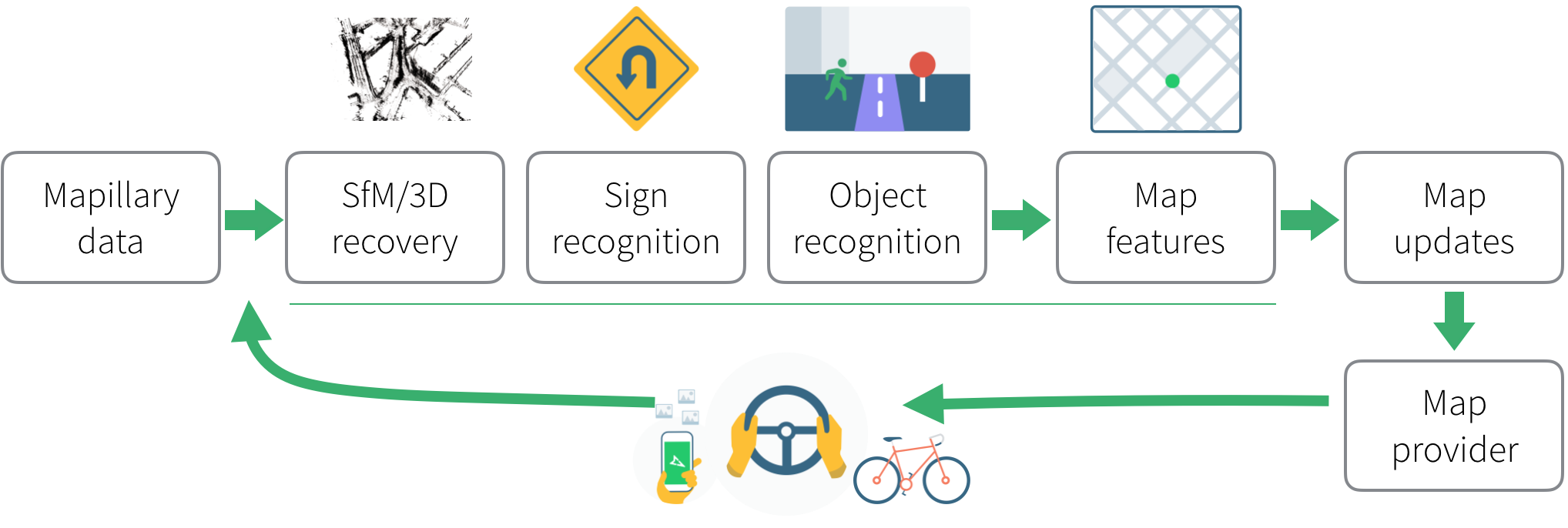 Mapillary's processing pipeline—from images to map data
Mapillary's processing pipeline—from images to map data
HD Maps and Collaborative Mapping
HD maps consist of dense and accurate map data created for autonomous vehicles. One of the data sources for HD maps is map data generated from hardware-based mapping solutions that rely on stereo cameras, 360° camera rigs, LiDAR, radar, high-precision GPS, etc.
Hardware and sensor fusion are the key components, which significantly reduces the computer vision engineering efforts needed for data processing. The drawback is that the hardware is expensive, which prevents frequent map updates and fast-growing coverage. Even though such hardware is envisioned to be available in higher autonomy for safety in the future, it will still take us years to scale globally.
An alternative data source for HD maps is collaborative mapping with monocular cameras and GPS measurements. This means a large number of people, who might have different direct objectives, are capturing images into a pool of shared data.
 Collobrative Mapping with diverse consumer-grade devices
Collobrative Mapping with diverse consumer-grade devices
This approach has several advantages:
Low costs—no need for high-end equipment; simple devices with a camera and GPS, such as smartphones and action cameras, can be used.
Fast-growing global coverage—anyone, anywhere, anytime can contribute.
Live updates—instead of batch processing, the imagery flows in and gets processed on a continuous basis.
The downside of that approach is that it requires sophisticated software development. To enable mapping with monocular cameras and low-precision GPS, computer vision and deep learning algorithms need to be developed to recover information directly from images, which otherwise would be obtained from direct measurements with high-end sensors (e.g. 3D point clouds from LiDAR).
Additional efforts are required to handle sensor calibration, noisy measurements, and modeling. What is good, though, is that the investments into computer vision will yield you a system that can scale infinitely since it can be combined with many consumer-grade devices.
Challenges in Collaborative Mapping
With the development of computer vision and deep learning as well as the leap in computational power, we aim to solve collaborative mapping in a scalable way. The key components of our approach are:
Object Recognition and Scene Understanding: recognizing objects and scene semantics automatically from images
Structure from Motion (SfM): recovering the 3D scene structure and camera motions from images
Map Object Extraction: extracting map objects by combining object recognition and 3D information from SfM
 Components of Mapillary's computer vision technology
Components of Mapillary's computer vision technology
By combining these components, we are able to automatically detect objects from geotagged images and determine their location on the map. But to make it work, we need to address a number of challenges. Here are some examples of the solutions we have been developing for these in Mapillary.
1. Moving Objects. With Structure from Motion, we would like to recover the camera motion with respect to the static scene. Other moving objects in the scene can cause confusion to the algorithm. Specifically, the typical issue could be that we recover the relative motion between the camera and another moving object, e.g. a bus.
We need a way to differentiate between the camera motions in space and such "distracting motions". We address this by using semantic understanding—identifying the moving objects in the scene and ignoring those in the Structure from Motion algorithm (read more about improving 3D reconstruction with semantic understanding).
 Moving object removal for SfM. Left: original image. Middle: semantic segmentation for the image. Right: binary mask with white for included segmentation classes and black for excluded. Excluded classes are vehicle, pedestrian, and sky, among others.
Moving object removal for SfM. Left: original image. Middle: semantic segmentation for the image. Right: binary mask with white for included segmentation classes and black for excluded. Excluded classes are vehicle, pedestrian, and sky, among others.
2. Diverse Camera Models. In collaborative mapping, images are captured with different camera models ranging from dashcams and action cameras to mobile phones and 360° cameras. Therefore, we’ve built supports for different camera models (pinhole, fisheye and equirectangular models). To estimate calibration parameters, e.g. unknown focal length, radial distortion, etc., we’ve built a solution for self-calibration from multiple images. We also maintain a database for different camera models that serves as prior information for further optimization.
3. Map updates. The traditional SfM pipeline is designed for static and batch processing. However, map updates need to be incremental, scalable, and consistent, as the images are flowing into the collaborative system continuously. We’ve developed a region-based approach that enables distributed map updates guided by GPS locations. The key to the success of this approach is to ensure consistent updates for neighboring regions. This way, we are able to generate map updates continuously and consistently on a global scale.
4. Annotations. For us to teach the computer to "see", we need a set of data that it can train on to learn to identify things correctly. This dataset needs to be manually annotated. The more precise and diverse the annotations, the better the algorithm that learns from it will perform in different situations. But also, the more time-consuming it is to create such a dataset.
In Mapillary, we’ve created the Mapillary Vistas Dataset and use it for training our deep learning algorithm. To speed up the learning process, we’ve also built a "Human in the Loop" component that is integrated into our database. This enables direct human feedback to the output of the deep learning algorithms, which reduces the turnaround time for the algorithm to learn from its mistakes (and successes).
 Examples of pixel-wise annotated images from the Mapillary Vistas Dataset
Examples of pixel-wise annotated images from the Mapillary Vistas Dataset
5. Rare objects. Detecting rare objects is key to map updates and, subsequently, safety on the road. By rare objects, we mean that some object annotations are better represented in the training dataset than others, and so the algorithm will not learn to detect some objects as well as others. For instance, a bicycle is a much more common object on the road than a koala.
We have developed a few techniques to compensate for the rarity of annotations. While it would be a bit too long to go into the details of that here, we invite you to take a look at the research findings that we regularly share from our computer vision research team and use in our processing technology.
Summing up
Mapillary’s goal is to build a processing platform for extracting map data from street-level images contributed by anyone. With the help of computer vision, we’re developing a solution that is scalable and device agnostic. This means that lots of different actors in the autonomous driving sector and the mapping sector can collaborate, which in turn will serve both sectors in general by providing faster and cheaper updates to accurate, comprehensive maps.
/Yubin