Human in the Loop: Perfecting AI Algorithms

We’ve been asked quite regularly whether there’s any way to help improve our computer vision detection algorithms. Some people want to point out (false) detections, while others suggest they could annotate certain objects to create new learning data for the algorithms. Both of these examples tie into a concept called Human in the Loop, which means including human feedback into the learning loop of the machine in order to help it improve faster.
The Human in the Loop approach is used by lots of AI developers, including Google and Facebook. The reason for this is that no matter how great your model accuracy, there will always be some extreme cases that are too difficult for the algorithm to handle. It’s very hard to improve on this without human intervention.
At Mapillary, involving human feedback in the loop helps us tackle those few percent of difficult cases. As a result, we get verified object data even for the cases that the computer was not sure about, as well as improve the algorithms by feeding them examples of those tough cases.
The collaborative nature of the Mapillary platform means that anyone can jump in and help—this is what will let us scale up. In addition, if people can select what they work on, they will choose what they most care about, which in turn sends us a signal about what to prioritize as we develop the algorithms.
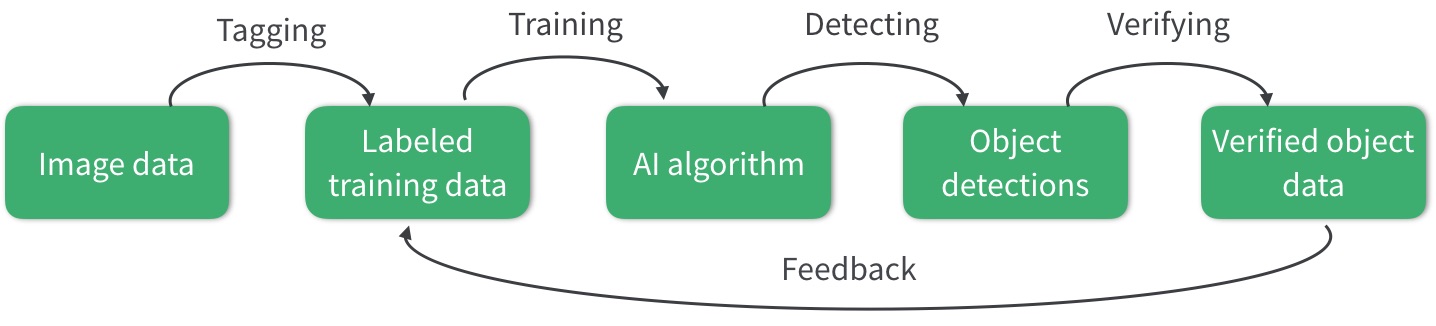
Human input in the machine learning loop at Mapillary
The above graph outlines Mapillary’s Human in the Loop approach. It starts with image data, which for Mapillary today means more than 200 million images from 190 countries all over the world, gathered via the collaboration of lots of different actors from individuals to whole countries. Our platform is device agnostic, which means that anyone with a camera can contribute.
From this large pool, we are able to select a very diverse sample of images for training our computer vision algorithms. For this, the images need to be manually annotated. Every pixel in the training dataset gets tagged with the correct label—like we have done in the Mapillary Vistas Dataset. This is the first step where human input is needed, so that we would have a starting point for teaching the computer to "see".
This training data is the basis for developing the computer vision models for detecting different objects in images. By showing the computer enough examples of each object, we can teach it to understand what it takes for something to be a car, a tree, or a tuk tuk. The more different examples of the same type of object the computer sees, the better it will be able to later recognize it with high accuracy and reliability in previously unseen scenes.
Once the models have been trained on the manually tagged training data, they’re used on all Mapillary imagery for traffic sign detection and semantic segmentation. Since no algorithm is 100% accurate, you will sometimes see objects that are incorrectly labeled or where the segment outlines are not precisely following the object in the image when you look at AI detections on the Mapillary web. The same applies to traffic signs: they can vary a lot in appearance, and we automatically detect over 900 different ones but it takes more work to hit the final remaining percentage points in accuracy.
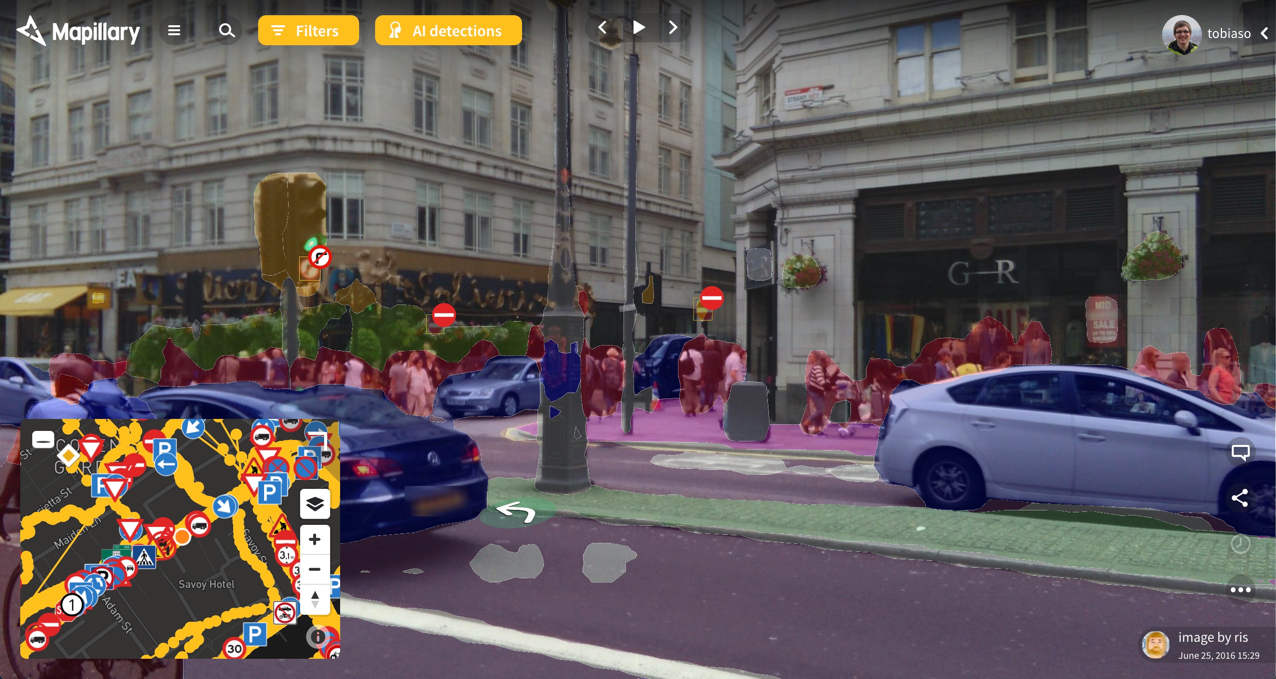
Traffic sign detection and semantic segmentation
This is where human input is incorporated for the second time. For every detection, a human is able to confirm whether it is right or wrong. This will turn detection data into verified detection data. On the one hand, this means we can instantly improve the data available on the Mapillary platform. On the other hand, the verifications provide feedback to the computer vision algorithms.
In addition to simple verification of correct/incorrect, if the detection is wrong, a human will be able to correct it. This can mean both choosing the right label and adjusting the boundaries of the segment on the image. In principle, this is tagging that takes place in the verification stage, and it creates even more comprehensive training data for the machine to learn from and become better.
All the feedback gets incorporated into the training data—and this is how the loop is connected. Now the AI algorithm can be re-trained with even more data as input and the object detections will turn out more accurate the next time around. And with a collaborative platform open to anyone’s input, the gradual improvements will follow demand both in terms of scale and what to work on first.
/Tobias